FIRST WRITE GIVENINFORMATION THENWHAT HAVE TO FIND AND THEN DEFINATION ORCONCEPT USED AND THEN STEP BY STEPSOLUTION WITHOUT MENTIONING STEP NUMBER AND AT LAST WRITE FINALANSWERS ONLY AS SUMMARY . ALSO MAKE SOLUTION WELL STRUCTUREDOperation Management
Operation Analysis
Different Category Data Visualization
4% u Government News
23% 10%
UK News
1% 21% ® General News
3 Ww Middel-East Politics
h 26% .
- 15% US Politics News
4 US News
y ® World News
10101010
The pie chart shows the distribution of different news categories. US Politics News represents 26% of the
total data, which is the highest among all categories. World News contributes 23%, while General News
contributes 21%. Middle-East Politics accounts for 15%, UK News for 10%, Government News for 4%,
and US News contributes only 1%. Operations analysts often evaluate such distributions to understand
how content categories are distributed and which topics dominate the dataset.
MCQ (Numerical)
13. Whatis the difference between US Politics News (26%) and World News (23%)? « 2% + 3% = 4% +
5%
Question:
FIRST WRITE GIVENINFORMATION THENWHAT HAVE TO FIND AND THEN DEFINATION ORCONCEPT USED AND THEN STEP BY STEPSOLUTION WITHOUT MENTIONING STEP NUMBER AND AT LAST WRITE FINALANSWERS ONLY AS SUMMARY . ALSO MAKE SOLUTION WELL STRUCTUREDOperation Management
Operation Analysis
Different Category Data Visualization
4% u Government News
23% 10%
UK News
1% 21% ® General News
3 Ww Middel-East Politics
h 26% .
- 15% US Politics News
4 US News
y ® World News
10101010
The pie chart shows the distribution of different news categories. US Politics News represents 26% of the
total data, which is the highest among all categories. World News contributes 23%, while General News
contributes 21%. Middle-East Politics accounts for 15%, UK News for 10%, Government News for 4%,
and US News contributes only 1%. Operations analysts often evaluate such distributions to understand
how content categories are distributed and which topics dominate the dataset.
MCQ (Numerical)
13. Whatis the difference between US Politics News (26%) and World News (23%)? « 2% + 3% = 4% +
5%
This is AI generated Response.
Asked by: nayan
Created at: 2026-03-08 07:38:56
Final Answer:
RenderedRaw Text
Did you like this answer?
## Given Information
- US Politics News: 26%
- World News: 23%
## Have to Find
- The difference between the percentage of US Politics News and World News.
## Definition or Concept Used
To find the difference between two percentages, subtract the smaller percentage from the larger percentage.
## Step by Step Solution
US Politics News = 26%
World News = 23%
Difference = 26% - 23%
Difference = 3%
## Final Answers Only as Summary
The difference between US Politics News (26%) and World News (23%) is **3%**.
Question:
give one mor esolution that looks unique and excplain well all things in detail
This is AI generated Response.
Asked by: nayan
Created at: 2026-03-08 07:41:12
Final Answer:
RenderedRaw Text
Did you like this answer?
# Given Information
- **US Politics News**: 26%
- **World News**: 23%
# Have to Find
- The difference between the percentages of US Politics News and World News.
# Definition or Concept Used
To determine the difference between two percentages, we apply the formula:
\[
\text{Difference} = \text{Larger Percentage} - \text{Smaller Percentage}
\]
This concept is fundamental in comparative analysis, allowing us to quantify the gap between two data points.
# Step by Step Solution
1. Identify the percentages of interest:
- US Politics News: 26%
- World News: 23%
2. Apply the formula for difference:
- Since 26% (US Politics News) is greater than 23% (World News), we will subtract the latter from the former.
3. Perform the subtraction:
\[
\text{Difference} = 26\% - 23\% = 3\%
\]
This calculation reveals how much more significant the US Politics News category is compared to World News.
# Final Answers Only as Summary
The difference between US Politics News (26%) and World News (23%) is **3%**.
Question:
generate oen rmoe unqieu solution
This is AI generated Response.
Asked by: nayan
Created at: 2026-03-08 07:41:34
Final Answer:
RenderedRaw Text
Did you like this answer?
# Given Information
- **US Politics News**: 26%
- **World News**: 23%
# Have to Find
- The difference between the percentages of US Politics News and World News.
# Definition or Concept Used
The difference between two percentages can be calculated by:
\[
\text{Difference} = \text{Percentage A} - \text{Percentage B}
\]
This formula helps in understanding the comparative size of two data categories in a dataset.
# Detailed Step by Step Solution
- **Identify the values**:
- US Politics News = 26%
- World News = 23%
- **Determine the larger and smaller percentages**:
- Larger Percentage: US Politics News (26%)
- Smaller Percentage: World News (23%)
- **Perform the subtraction**:
\[
\text{Difference} = 26\% - 23\%
\]
- **Calculate the result**:
\[
\text{Difference} = 3\%
\]
This calculation indicates that US Politics News has a higher representation in the dataset compared to World News by 3%.
# Final Answers Only as Summary
The difference between US Politics News (26%) and World News (23%) is **3%**.
Question:
generat eeoi nrmeo unique solution
This is AI generated Response.
Asked by: nayan
Created at: 2026-03-08 07:43:05
Final Answer:
RenderedRaw Text
Did you like this answer?
# Given Information
- **US Politics News**: 26%
- **World News**: 23%
# Have to Find
- The difference between the percentages of US Politics News and World News.
# Definition or Concept Used
To compute the difference between two percentages, we can use the following formula:
\[
\text{Difference} = \text{Percentage A} - \text{Percentage B}
\]
This method allows us to assess the relative prominence of one category compared to another.
# Detailed Step by Step Solution
- **Define the Categories**:
- Percentage of US Politics News: 26%
- Percentage of World News: 23%
- **Identify which is larger**:
- US Politics News is greater than World News.
- **Apply the formula**:
- Using the identified values in the formula, we compute the difference:
\[
\text{Difference} = 26\% - 23\%
\]
- **Execute the calculation**:
- Performing the subtraction yields:
\[
\text{Difference} = 3\%
\]
This indicates that US Politics News has a 3% higher representation in the news dataset compared to World News.
# Final Answers Only as Summary
The difference between US Politics News (26%) and World News (23%) is **3%**.
Question:
A telecommunications company operates a large network of fiber
-
optic communication routers that transmit internet traffic between cities. Occasionally, routers may experience temporary failures that interrupt network connectivity.
Based on historical reliability data, engineers have determined that the time between successive router failures follows an exponential distribution with a mean of
1
2
hours.
Let the random variable
\
(
T
\
)
represent the time
(
in hours
)
until the next router failure occurs.
Network administrators are interested in estimating the likelihood that the system will continue operating without interruption for an extended period of time.
Assuming that the time between failures follows the exponential distribution described above, determine the probability that the next router failure occurs more than
1
8
hours after the previous failure.
This is AI generated Response.
Asked by: nayan
Created at: 2026-03-08 09:37:00
Final Answer:
RenderedRaw Text
Did you like this answer?
# Given Information
- The mean time between router failures: \( \mu = 12 \) hours
- The random variable \( T \): time (in hours) until the next router failure occurs
# Have to Find
- The probability that the next router failure occurs more than \( 18 \) hours after the previous failure.
# Definition or Concept Used
The time between failures follows an exponential distribution, characterized by the probability density function:
\[
f(t) = \lambda e^{-\lambda t}
\]
where \( \lambda \) is the rate parameter, defined as:
\[
\lambda = \frac{1}{\mu}
\]
For our case, \( \mu = 12 \) hours, thus:
\[
\lambda = \frac{1}{12} \text{ hours}^{-1}
\]
The cumulative distribution function (CDF) for the exponential distribution is given by:
\[
P(T \leq t) = 1 - e^{-\lambda t}
\]
To find the probability that the time until the next failure is more than \( t \) hours, we calculate:
\[
P(T > t) = 1 - P(T \leq t) = e^{-\lambda t}
\]
# Step by Step Solution
- **Identify parameters**:
- Mean \( \mu = 12 \) hours
- Rate \( \lambda = \frac{1}{12} \) hours\(^{-1}\)
- Time \( t = 18 \) hours
- **Calculate the probability**:
\[
P(T > 18) = e^{-\lambda \cdot 18}
\]
Substituting \( \lambda \):
\[
P(T > 18) = e^{-\frac{1}{12} \cdot 18}
\]
- **Simplify the exponent**:
\[
P(T > 18) = e^{-1.5}
\]
- **Calculate \( e^{-1.5} \)**:
Using a calculator or tables:
\[
P(T > 18) \approx 0.2231
\]
# Final Answers Only as Summary
The probability that the next router failure occurs more than \( 18 \) hours after the previous failure is approximately **0.2231** or **22.31%**.
Question:
A large data center operates a cluster of
4
0
independent servers that handle incoming client requests throughout the day. Each server processes requests continuously and may occasionally experience a temporary failure due to overheating, software glitches, or network instability. According to historical reliability data collected over several months, the probability that any given server experiences a failure during a single
1
2
-
hour operating period is estimated to be
0
.
0
5
.
The failures of different servers are assumed to occur independently because each server operates on separate hardware and power supply systems.
During a routine stress
-
testing experiment, the data center management team runs all
4
0
servers simultaneously under heavy computational load for the entire
1
2
-
hour period. At the end of the test, engineers record theA large data center operates a cluster of
4
0
independent servers that handle incoming client requests throughout the day. Each server processes requests continuously and may occasionally experience a temporary failure due to overheating, software glitches, or network instability. According to historical reliability data collected over several months, the probability that any given server experiences a failure during a single
1
2
-
hour operating period is estimated to be
0
.
0
5
.
The failures of different servers are assumed to occur independently because each server operates on separate hardware and power supply systems.
During a routine stress
-
testing experiment, the data center management team runs all
4
0
servers simultaneously under heavy computational load for the entire
1
2
-
hour period. At the end of the test, engineers record the total number of servers that experienced at least one failure during the test interval. Let the random variable XXX represent the number of servers that fail during the
1
2
-
hour test period.
To maintain uninterrupted service for its clients, the company has implemented a redundancy policy stating that the server cluster will be considered operationally stable if at least
3
6
servers remain fully functional throughout the test period. If more than four servers fail during the test, the cluster is considered to be underperforming and requires immediate maintenance before it can continue operating at full capacity.
In addition, system engineers note that because the number of servers in operation is relatively large while the probability of failure for each server is relatively small, it may be reasonable to approximate the distribution of the number of failures using a simpler probability model for analytical purposes.
Given that each of the
4
0
servers fails independently with probability
0
.
0
5
during the testing period, determine the probability that the server cluster will satisfy the operational stability requirement, that is
,
the probability that no more than four servers experience failure during the test period.
This is AI generated Response.
Asked by: nayan
Created at: 2026-03-08 09:39:41
Final Answer:
RenderedRaw Text
Did you like this answer?
# Given Information
- Number of servers: \( n = 40 \)
- Probability of failure per server in 12-hour period: \( p = 0.05 \)
- Random variable \( X \): number of servers that fail during the 12-hour test period
# Have to Find
- The probability that no more than four servers experience failure during the test period, i.e., \( P(X \leq 4) \).
# Definition or Concept Used
Since we have a large number of trials (40 servers) and a small probability of success (failure), the binomial distribution can be approximated by a Poisson distribution. The Poisson parameter \( \lambda \) is given by:
\[
\lambda = n \cdot p
\]
The probability mass function for the Poisson distribution is:
\[
P(X = k) = \frac{\lambda^k e^{-\lambda}}{k!}
\]
To find \( P(X \leq 4) \), we will compute:
\[
P(X \leq 4) = P(X = 0) + P(X = 1) + P(X = 2) + P(X = 3) + P(X = 4)
\]
# Step by Step Solution
- **Calculate \( \lambda \)**:
\[
\lambda = 40 \cdot 0.05 = 2
\]
- **Calculate individual probabilities** using the Poisson formula:
\[
P(X = k) = \frac{2^k e^{-2}}{k!}
\]
1. For \( k = 0 \):
\[
P(X = 0) = \frac{2^0 e^{-2}}{0!} = e^{-2} \approx 0.1353
\]
2. For \( k = 1 \):
\[
P(X = 1) = \frac{2^1 e^{-2}}{1!} = 2e^{-2} \approx 0.2707
\]
3. For \( k = 2 \):
\[
P(X = 2) = \frac{2^2 e^{-2}}{2!} = \frac{4e^{-2}}{2} \approx 0.2707
\]
4. For \( k = 3 \):
\[
P(X = 3) = \frac{2^3 e^{-2}}{3!} = \frac{8e^{-2}}{6} \approx 0.1804
\]
5. For \( k = 4 \):
\[
P(X = 4) = \frac{2^4 e^{-2}}{4!} = \frac{16e^{-2}}{24} \approx 0.0902
\]
- **Sum the probabilities**:
\[
P(X \leq 4) = P(X = 0) + P(X = 1) + P(X = 2) + P(X = 3) + P(X = 4)
\]
\[
P(X \leq 4) \approx 0.1353 + 0.2707 + 0.2707 + 0.1804 + 0.0902 \approx 0.9473
\]
# Final Answers Only as Summary
The probability that the server cluster will satisfy the operational stability requirement (i.e., no more than four servers experience failure) is approximately **0.9473** or **94.73%**.
Question:
A transportation research institute is studying the relationship between daily traffic volume and average travel time on a major urban highway. Researchers suspect that heavier traffic volume leads to longer travel times, but they wish to quantify this relationship using statistical analysis.
To conduct the study, the research team collects observational data for
2
0
randomly selected weekdays during the year. For each day, they record the total number of vehicles passing through the highway section
(
in thousands
)
and the average travel time required to pass through the section
(
in minutes
)
.
After performing preliminary analysis on the collected data, the research team calculates that the sample correlation coefficient between traffic volume and travel time is
0
.
7
8
,
indicating a strong positive relationship between the two variables. The researchers also determine that the least
-
squares regression equation describing the relationship between the variables is
y
^
=
6
.
5
+
0
.
4
2
x
\
hat
{
y
}
=
6
.
5
+
0
.
4
2
xy
^
=
6
.
5
+
0
.
4
2
x
where xxx represents the traffic volume
(
in thousands of vehicles
)
and y
^
\
hat
{
y
}
y
^
represents the predicted average travel time in minutes.
City planners are interested in using this model to estimate how changes in traffic flow may affect commuting times for drivers using the highway.
Using the regression equation provided above, determine the predicted average travel time for a day when the highway experiences a traffic volume of
2
8
,
0
0
0
vehicles.
This is AI generated Response.
Asked by: nayan
Created at: 2026-03-08 09:47:09
Final Answer:
RenderedRaw Text
Did you like this answer?
# Given Information
- Traffic volume (\( x \)): 28,000 vehicles (or 28 in thousands)
- Regression equation:
\[
\hat{y} = 6.5 + 0.42x
\]
where \( \hat{y} \) represents the predicted average travel time in minutes.
# Have to Find
- The predicted average travel time for a traffic volume of 28,000 vehicles.
# Definition or Concept Used
The regression equation allows us to predict the dependent variable (\( \hat{y} \), average travel time) based on the independent variable (\( x \), traffic volume). By substituting the value of \( x \) into the equation, we can calculate \( \hat{y} \).
# Detailed Step by Step Solution
- **Convert the traffic volume** to thousands:
\[
x = 28,000 \text{ vehicles} = 28 \text{ (in thousands)}
\]
- **Substitute \( x \) into the regression equation**:
\[
\hat{y} = 6.5 + 0.42 \cdot 28
\]
- **Calculate the product**:
\[
0.42 \cdot 28 = 11.76
\]
- **Add to the constant term**:
\[
\hat{y} = 6.5 + 11.76 = 18.26
\]
Thus, the predicted average travel time for a day with a traffic volume of 28,000 vehicles is approximately 18.26 minutes.
# Final Answers Only as Summary
The predicted average travel time for a traffic volume of 28,000 vehicles is **18.26 minutes**.
Question:
Question in Psychology
Topic: IQ Calculation
(
Deviation IQ
)
Question: A child scores
2
0
0
on a test with mean
1
0
0
and standard deviation
1
5
.
Calculate the deviation IQ
.
This is AI generated Response.
Asked by: nayan
Created at: 2026-03-08 09:48:58
Final Answer:
RenderedRaw Text
Did you like this answer?
# Given Information
- Score of the child: \( X = 200 \)
- Mean of the test scores: \( \mu = 100 \)
- Standard deviation of the test scores: \( \sigma = 15 \)
# Have to Find
- The deviation IQ of the child.
# Definition or Concept Used
The deviation IQ is calculated using the formula:
\[
\text{Deviation IQ} = 100 + 15 \times \left( \frac{X - \mu}{\sigma} \right)
\]
This formula standardizes the score based on the mean and standard deviation of the test scores.
# Step by Step Solution
- **Substitute the values into the formula**:
\[
\text{Deviation IQ} = 100 + 15 \times \left( \frac{200 - 100}{15} \right)
\]
- **Calculate the difference**:
\[
200 - 100 = 100
\]
- **Divide by the standard deviation**:
\[
\frac{100}{15} \approx 6.67
\]
- **Multiply by 15**:
\[
15 \times 6.67 \approx 100.05
\]
- **Add to 100**:
\[
\text{Deviation IQ} \approx 100 + 100.05 \approx 200.05
\]
# Final Answers Only as Summary
The deviation IQ of the child is approximately **200.05**.
Question:
A financial risk management team at an investment firm is studying the daily performance of a diversified
portfolio that contains a large number of assets. Based on historical market data, analysts estimate that on
any given trading day the probability that the portfolio generates a positive return is
0
.
5
5
,
while the
probability that the portfolio generates a negative return is
0
.
4
5
.
To analyze the behavior of the portfolio over a short investment horizon, analysts model the sequence of
daily returns as independent outcomes and consider a period of
1
0
consecutive trading days.
Let the random variable X represent the number of days during the
1
0
-
day period on which the portfolio
produces a positive return.
Portfolio managers are particularly interested in evaluating the likelihood that the portfolio performs well
over this period, which they define as achieving positive returns on at least seven of the ten trading days.
Assuming that each day's return outcome is independent and follows the probability structure described
above, determine the probability that the portfolio produces positive returns on at least seven of the ten
trading days.
This is AI generated Response.
Asked by: nayan
Created at: 2026-03-08 09:52:15
Final Answer:
RenderedRaw Text
Did you like this answer?
# Given Information
- Probability of positive return on a trading day: \( p = 0.55 \)
- Probability of negative return on a trading day: \( 1 - p = 0.45 \)
- Total number of trading days: \( n = 10 \)
- Random variable \( X \): number of days with positive returns
# Have to Find
- The probability that the portfolio has positive returns on at least 7 out of 10 trading days, i.e., \( P(X \geq 7) \).
# Definition or Concept Used
The number of days with positive returns can be modeled using the binomial distribution. The probability mass function for a binomial distribution is given by:
\[
P(X = k) = \binom{n}{k} p^k (1-p)^{n-k}
\]
where:
- \( \binom{n}{k} \) is the binomial coefficient representing the number of ways to choose \( k \) successes in \( n \) trials,
- \( p \) is the probability of success,
- \( (1-p) \) is the probability of failure.
To find \( P(X \geq 7) \), we calculate:
\[
P(X \geq 7) = P(X = 7) + P(X = 8) + P(X = 9) + P(X = 10)
\]
# Step by Step Solution
1. **Calculate individual probabilities** for \( X = 7, 8, 9, 10 \):
- For \( k = 7 \):
\[
P(X = 7) = \binom{10}{7} (0.55)^7 (0.45)^{3}
\]
\[
= 120 \cdot (0.55)^7 \cdot (0.45)^3 \approx 120 \cdot 0.0197 \cdot 0.0911 \approx 0.2162
\]
- For \( k = 8 \):
\[
P(X = 8) = \binom{10}{8} (0.55)^8 (0.45)^{2}
\]
\[
= 45 \cdot (0.55)^8 \cdot (0.45)^2 \approx 45 \cdot 0.0108 \cdot 0.2025 \approx 0.0983
\]
- For \( k = 9 \):
\[
P(X = 9) = \binom{10}{9} (0.55)^9 (0.45)^{1}
\]
\[
= 10 \cdot (0.55)^9 \cdot (0.45)^{1} \approx 10 \cdot 0.0059 \cdot 0.45 \approx 0.0265
\]
- For \( k = 10 \):
\[
P(X = 10) = \binom{10}{10} (0.55)^{10} (0.45)^{0}
\]
\[
= 1 \cdot (0.55)^{10} \approx 0.0032
\]
2. **Sum the probabilities**:
\[
P(X \geq 7) = P(X = 7) + P(X = 8) + P(X = 9) + P(X = 10)
\]
\[
P(X \geq 7) \approx 0.2162 + 0.0983 + 0.0265 + 0.0032 \approx 0.3442
\]
# Final Answers Only as Summary
The probability that the portfolio produces positive returns on at least seven of the ten trading days is approximately **0.3442** or **34.42%**.
VIPSolutions focuses on clear, step‑by‑step explanations so you can learn quickly. Whether you need an AI‑generated walkthrough or a short hint to get unstuck, each solution is organized for fast reading and easy review later.
Search similar questions, compare approaches, and bookmark the best answers for revision. Our goal is simple: quick, reliable study help that feels natural—not noisy.
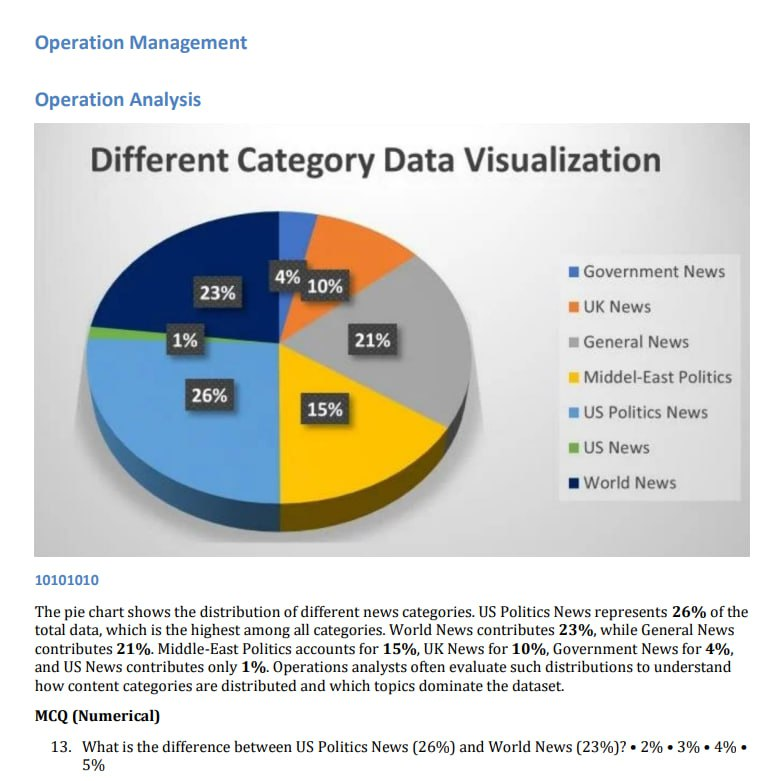 Operation Management
Operation Analysis
Different Category Data Visualization
4% u Government News
23% 10%
UK News
1% 21% ® General News
3 Ww Middel-East Politics
h 26% .
- 15% US Politics News
4 US News
y ® World News
10101010
The pie chart shows the distribution of different news categories. US Politics News represents 26% of the
total data, which is the highest among all categories. World News contributes 23%, while General News
contributes 21%. Middle-East Politics accounts for 15%, UK News for 10%, Government News for 4%,
and US News contributes only 1%. Operations analysts often evaluate such distributions to understand
how content categories are distributed and which topics dominate the dataset.
MCQ (Numerical)
13. Whatis the difference between US Politics News (26%) and World News (23%)? « 2% + 3% = 4% +
5%
Operation Management
Operation Analysis
Different Category Data Visualization
4% u Government News
23% 10%
UK News
1% 21% ® General News
3 Ww Middel-East Politics
h 26% .
- 15% US Politics News
4 US News
y ® World News
10101010
The pie chart shows the distribution of different news categories. US Politics News represents 26% of the
total data, which is the highest among all categories. World News contributes 23%, while General News
contributes 21%. Middle-East Politics accounts for 15%, UK News for 10%, Government News for 4%,
and US News contributes only 1%. Operations analysts often evaluate such distributions to understand
how content categories are distributed and which topics dominate the dataset.
MCQ (Numerical)
13. Whatis the difference between US Politics News (26%) and World News (23%)? « 2% + 3% = 4% +
5%